JOB PILOT
AI Job Application Automation
The job market is brutal. AI screens out resumes before a human ever sees them, and hundreds of applicants compete for every role. So I flipped the script: if AI is making it harder to get hired, I'll build my own AI to fight back.
Overview
I designed and built this entire product solo: the setup wizard UX (prototyped as interactive HTML/CSS), the pipeline architecture, and every line of Python underneath. The system scrapes Product Design roles from LinkedIn and BuiltIn, uses the Anthropic API (Claude Sonnet) to tailor resumes and cover letters per role, generates pixel-precise PDFs via ReportLab, and pushes everything to a Notion Kanban dashboard. Runs daily at 8 AM via cron. Gmail integration auto-tracks interview invitations, rejections, and manually-applied jobs.
Scraping
Playwright-powered headless browsers scrape LinkedIn (public guest search across 8 cities) and BuiltIn (9 search combinations across city subdomains). Anti-detection with random delays, realistic user agents, and limited pagination.
AI Tailoring
Claude Sonnet generates tailored resume copy, cover letters with a 100-combination variation engine, pre-filled application responses, and match scores, all constrained by a system prompt with hard anti-hallucination guardrails.
Problem Statement
I was spending 2-3 hours per day on my job search: scrolling LinkedIn, copying job descriptions, manually rewriting resume bullets to match each JD, writing cover letters from scratch, and tracking everything in a spreadsheet.
The insight: Most of that work was repetitive pattern-matching , exactly what an LLM is good at. The goal was to reduce daily effort to ~15-20 minutes of review and final submission while maintaining or improving the quality of application materials. The system handles discovery, filtering, tailoring, and tracking automatically so I can focus on evaluating company fit, tweaking tone, and hitting submit.
Architecture
The pipeline is a four-stage conveyor belt that runs every morning at 8 AM, with a post-pipeline Gmail integration layer.
SCRAPING
- LinkedIn (8 cities)
- BuiltIn (9 searches)
- Public guest pages
FILTERING
- Title match
- Location + salary
- Fuzzy dedup (85%)
TAILORING
- Claude API
- Resume + cover letter
- PDF generation
DELIVERY
- Notion Kanban
- Match scores
- App responses
POST-PIPELINE
Gmail Tracker scans inbox for interview/rejection emails and updates Notion. Gmail Backfill finds "thank you for applying" emails not in Notion and adds them.
Setup Wizard
An 8-step onboarding flow that configures the entire pipeline. Everything stays local. Your data is saved to a config file on your machine and only sent to the Claude API when generating tailored materials.
Privacy-first
Your data stays local. Everything is saved to a config file on your machine. It's only sent to the Claude API when generating tailored materials, and never stored on any server.
Accuracy guarantee
The AI will only reference experience you enter during setup. It will never fabricate companies, inflate titles, or invent skills. Your real background is your strongest asset.
How It Works
Six scripts, one daily cron job, from raw listings to tailored applications
Scraping
Playwright-powered headless browsers scrape LinkedIn (public guest search across 8 cities) and BuiltIn (9 search combinations across city subdomains). V1 used authenticated browsing. LinkedIn's bot detection served wrong results, so V2 switched to public guest pages. Detail fetches capped at 5 per city to keep runtime under 15 minutes.
Filtering & Dedup
Filters by title match, excluded titles, max YoE, and $100K salary floor. Deduplicates across sources using exact hash + fuzzy string similarity (SequenceMatcher at 85%) + historical dedup against a seen_jobs.json ledger. "Stripe, Inc." on LinkedIn and "Stripe" on BuiltIn resolve to the same entry.
AI Tailoring Engine
Uses the Anthropic API (Claude Sonnet) to generate per-job tailored summaries, experience bullets (STAR format, real metrics), ATS keywords, match scores, cover letters via a 100-combination variation engine, and pre-filled application responses, all constrained by a system prompt with hard anti-hallucination guardrails.
Variation Engine
5 opening strategies × 5 experience leads × 4 closings = 100 structural combinations per cover letter, before any JD-specific content.
Guardrails
Locked work history in system prompt. No invented metrics or project references. Industry variant routing (fintech/healthtech/ecommerce/general).
Delivery & Tracking
Results push to a Notion Kanban board with match scores and tailored PDFs. Gmail Tracker scans for interview/rejection emails and updates statuses with priority logic (won't downgrade). Backfill catches manually-applied jobs by finding "thank you for applying" emails not in Notion.
Results
Running daily for ~10 days as of late March 2026. The system replaced most of the manual work without sacrificing quality.
100+
Tailored Resumes
Generated as print-ready PDFs
100+
Cover Letters
With structural variation
~15 min
Daily Effort
Down from 2-3 hours
$0.60
Daily Cost
~$0.06-0.10 per application
Go-To-Market
Autopilot isn't locked to one job title. I designed it as a multi-persona platform; the pipeline accepts a --role flag that reconfigures scraping queries, filtering logic, and tailoring prompts for any job function.
To validate market breadth, I ran the full pipeline for 10 different roles and captured the results. Each card shows real scrape volumes, match counts, and tailored outputs, demonstrating that the system scales across industries and seniority levels.

Software Engineer
330 scraped → 156 matched → 20 tailored
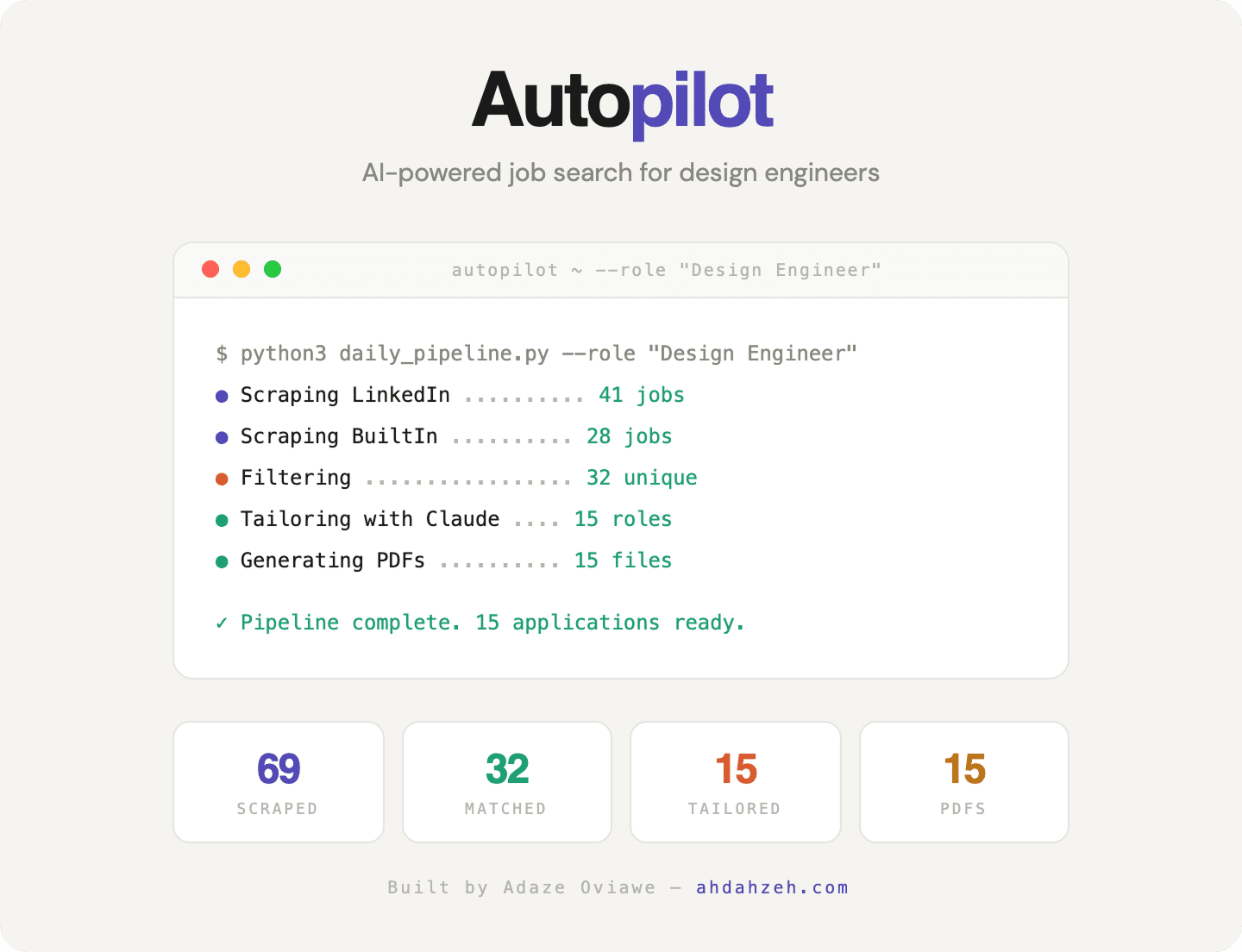
Design Engineer
69 scraped → 32 matched → 15 tailored
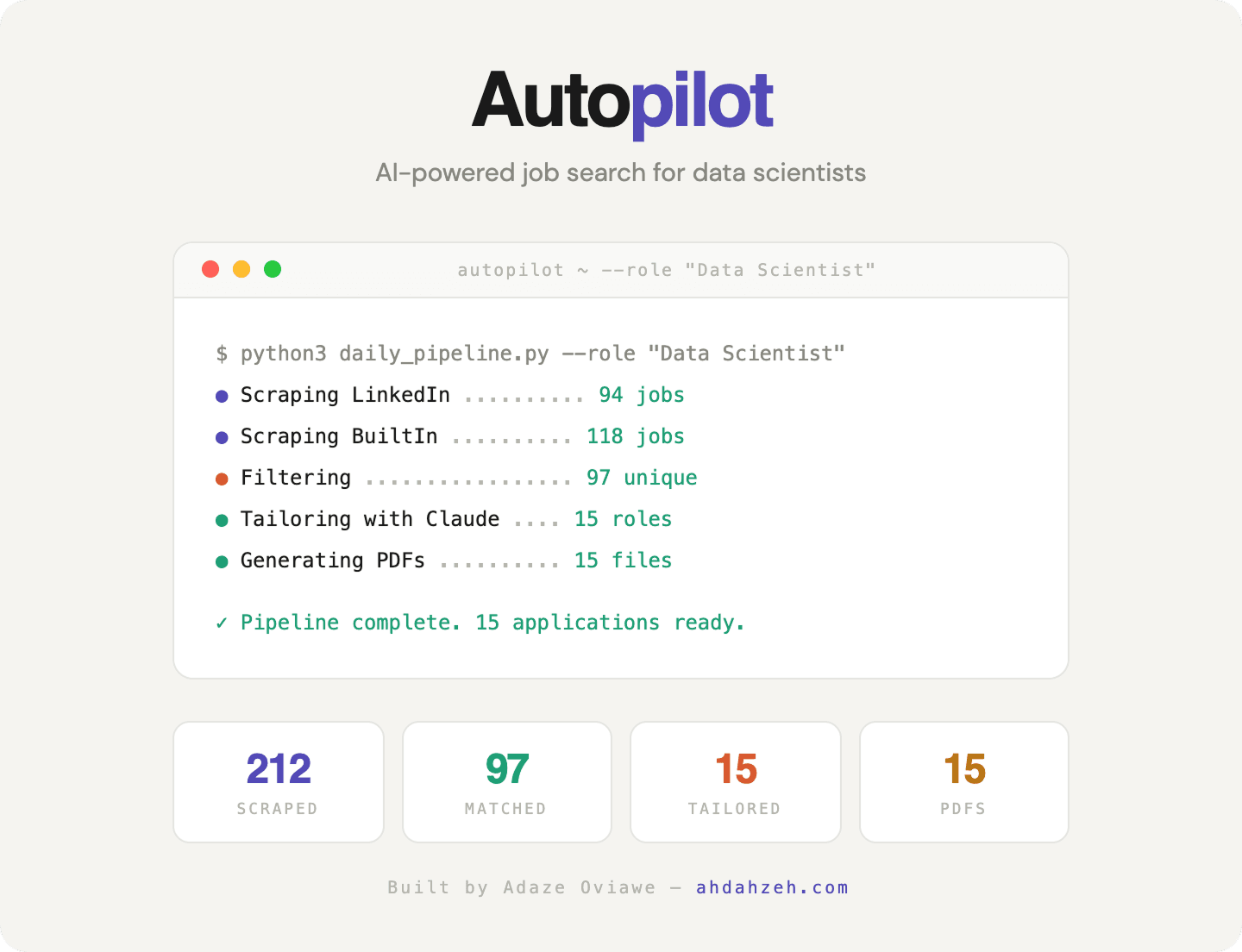
Data Scientist
212 scraped → 97 matched → 15 tailored
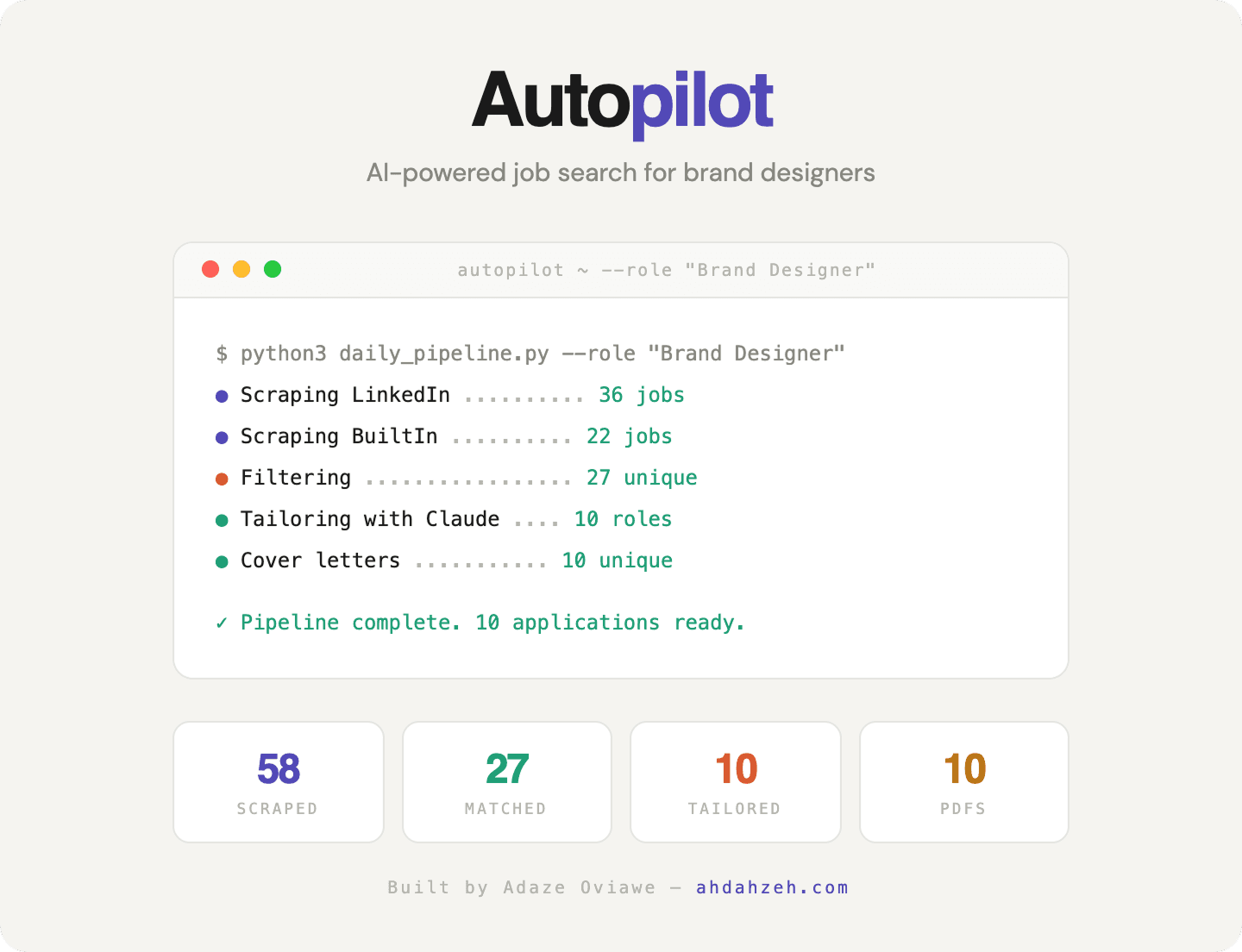
Brand Designer
58 scraped → 27 matched → 10 tailored
Market Insight
Volume scales with market size. Software Engineer and Product Manager roles return 300+ listings per run, while niche roles like Brand Designer and Content Strategist return 50–90. The pipeline adapts: smaller pools get higher tailoring ratios so every viable match gets a custom application.
Technical Decisions
Core
Python 3.12, Playwright (async), Anthropic API (Claude Sonnet)
PDF Generation
ReportLab, pixel-precise two-column layout matching Figma template
Dashboard
Native Kanban (React/Next.js), Gmail API (OAuth2), httpx (async HTTP)
Infrastructure
macOS cron (daily 8 AM), loguru (structured logs), python-dotenv
Public scraping over LinkedIn API
LinkedIn's official API doesn't expose job search. Authenticated headless browsing triggered bot detection and served wrong results. Public guest pages return accurate results without auth, at the cost of slightly less metadata.
ReportLab over HTML-to-PDF
My resume uses a specific two-column layout with precise font sizes and a divider at exactly 6.5 inches. HTML-to-PDF converters don't give pixel-level control. ReportLab lets me position every element by coordinates.
Fuzzy dedup over exact matching
"Stripe, Inc." on LinkedIn and "Stripe" on BuiltIn produce different hashes. The fuzzy matcher normalizes company names, strips suffixes, and uses SequenceMatcher at 85% to catch near-duplicates across sources.
Native Dashboard
The pipeline originally pushed everything to Notion, functional but impersonal. I built a native web dashboard to replace it: a Kanban board showing every job scraped, matched, applied to, and tracked. Match scores, resume and cover letter links, Gmail sync status, and pipeline stats all in one place.
What's Next
The core pipeline is running and proving itself daily. Here's what I'd build next if I kept pushing.
Multi-user SaaS
The config-based architecture is already multi-persona. The next step is turning it into a product with auth, per-user pipeline configs, and a shared job database. Pricing would follow a usage model: pay per tailored application.
Richer match scoring
Current scores are generated per-job at tailoring time. A better system would embed your resume and all job descriptions into a vector store, enabling semantic similarity search and ranking before any LLM call, faster, cheaper, and more accurate.
Outreach automation
The system knows which companies are hiring and which roles are strong matches. A natural extension: auto-draft personalized outreach messages to hiring managers at high-score companies, with the same variation engine used for cover letters.
Interview prep loop
Once a role moves to Interview status, the pipeline could generate a company research brief, predict likely questions from the JD, and produce tailored STAR-format answers using your actual experience, all before your first call.
Building Autopilot taught me that the most impactful design engineering happens when you own the problem end-to-end, from the first wireframe to the last cron job. The system runs daily, the dashboard surfaces everything in one view, and the pipeline is designed to scale to any job function.